大量に仕事をしている方も多いです ドキュメントあなたが学生であり、あなたがするべき千の仕事を持っているので、またはあなたがあなたの会社のためにそれらを書かなければならないので。 さらに、これに追加すると、多くの場合、にあるテキストをコピーする必要があります。 PDF、物事は私たちにとって少し難しくなる可能性があります。
PDFからテキストを簡単に抽出する
多くの人が見てきたように、デバイス Apple Mac オペレーティングシステムでカウント OS X と herramienta それは長い間私たちと一緒にいて、その使用法を知っている人はほとんどいません。 Automatorの.
これらの簡単な手順に従うことで、次のことを学ぶことができます。 PDFドキュメントからテキストを抽出する ツールで Automatorの そのアクションを保存して、将来必要な回数だけ使用できるようにします。

テキストを抽出するためのガイド
- まず第一に私たちがすべきことは Automatorアプリを起動します、で見つけることができます ドック/アプリケーション/ Automator (より速くしたい場合は、キーを押すだけです。 cmd +スペース そして、書きます Automatorの).
- 開いたら、ご要望があれば作成を選択します ワークフロー.
- 最初に選択する列になるように、XNUMXつの列があり、オプションが異なります。 ファイルとフォルダ.
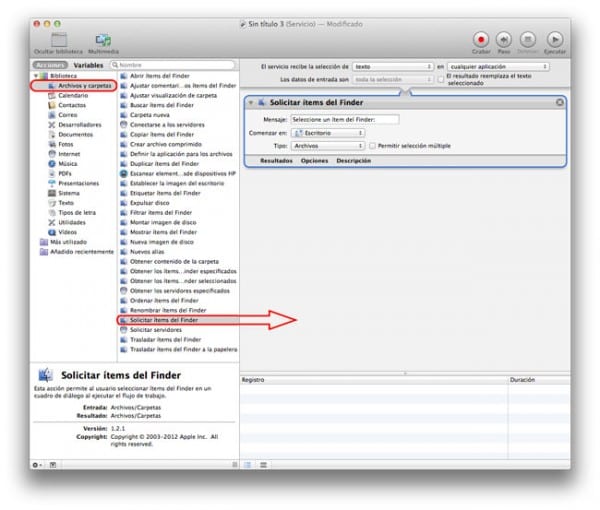
- これに続いて、XNUMX番目の列で私たちは探します ファインダーからアイテムをリクエストする、これを選択してXNUMX番目の列、右側のスペースにドラッグします。ここにすべての ワークフロー さまざまなオプションを含むボックスが表示されます。

- ステップ4が完了すると、最初の列、全体の左側の列に戻り、今回は選択します PDFファイル.
- XNUMX番目の列(中央の列)から、のアクションを選択します PDFからテキストを抽出する それを右側の領域にドラッグし、前のアクションの下にさまざまなオプションを残します。
- 最後のステップでは、このXNUMX番目のアクションから選択します PDFからテキストを抽出する のオプション RTF形式の出力 (リッチテキスト).

- 準備ができました。必要なのは それを保存、内部を押して行います メニュー/ファイル/保存、「」として保存しますPDFテキストを抽出」または決定したとおりに、アプリケーションとして保存します。
- これがすべて完了したら、ドキュメントをクリックして選択するだけです。 PDF 抽出したいもの。
このヒントが気に入った場合は、 Applelised このセクションには、このようなヒントやコツがたくさんあります。 チュートリアル.
出典:PacMac